Przykłady i zastosowania
W trakcie tej lekcji przyjrzymy się kilku przykładom algorytmów wariacyjnych oraz sposobom ich stosowania:
- Jak napisać własny algorytm wariacyjny
- Jak zastosować algorytm wariacyjny do znajdowania minimalnych wartości własnych
- Jak wykorzystać algorytmy wariacyjne do rozwiązywania zastosowań praktycznych
Zauważ, że framework Qiskit patterns można zastosować do wszystkich problemów, które tutaj przedstawiamy. Aby jednak uniknąć powtórzeń, kroki frameworka omówimy jawnie tylko w jednym przykładzie, uruchomionym na rzeczywistym sprzęcie.
Definicje problemów
Wyobraź sobie, że chcemy użyć algorytmu wariacyjnego do znalezienia wartości własnej następującej obserwabli:
Ta obserwabla ma następujące wartości własne:
Oraz stany własne:
# Added by doQumentation — required packages for this notebook
!pip install -q numpy qiskit qiskit-ibm-runtime rustworkx scipy
from qiskit.quantum_info import SparsePauliOp
observable_1 = SparsePauliOp.from_list([("II", 2), ("XX", -2), ("YY", 3), ("ZZ", -3)])
Własny VQE
Najpierw zobaczymy, jak ręcznie skonstruować instancję VQE, aby znaleźć najniższą wartość własną dla . Wykorzystamy przy tym różne techniki, które omówiliśmy w trakcie tego kursu.
def cost_func_vqe(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
return cost
from qiskit.circuit.library.n_local import n_local
from qiskit import QuantumCircuit
import numpy as np
reference_circuit = QuantumCircuit(2)
reference_circuit.x(0)
variational_form = n_local(
num_qubits=2,
rotation_blocks=["rz", "ry"],
entanglement_blocks="cx",
entanglement="linear",
reps=1,
)
raw_ansatz = reference_circuit.compose(variational_form)
raw_ansatz.decompose().draw("mpl")
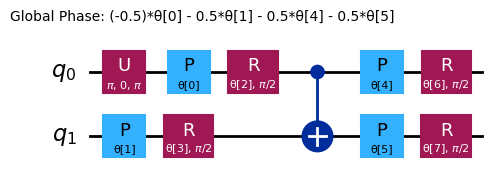
Zaczniemy od debugowania na lokalnych symulatorach.
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
Teraz ustawiamy początkowy zestaw parametrów:
x0 = np.ones(raw_ansatz.num_parameters)
print(x0)
[1. 1. 1. 1. 1. 1. 1. 1.]
Możemy zminimalizować tę funkcję kosztu, aby obliczyć optymalne parametry
# SciPy minimizer routine
from scipy.optimize import minimize
import time
start_time = time.time()
result = minimize(
cost_func_vqe,
x0,
args=(raw_ansatz, observable_1, estimator),
method="COBYLA",
options={"maxiter": 1000, "disp": True},
)
end_time = time.time()
execution_time = end_time - start_time
Return from COBYLA because the trust region radius reaches its lower bound.
Number of function values = 103 Least value of F = -5.999999998357189
The corresponding X is:
[2.27483579e+00 8.37593091e-01 1.57080508e+00 5.82932911e-06
2.49973063e+00 6.41884255e-01 6.33686904e-01 6.33688223e-01]
result
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -5.999999998357189
x: [ 2.275e+00 8.376e-01 1.571e+00 5.829e-06 2.500e+00
6.419e-01 6.337e-01 6.337e-01]
nfev: 103
maxcv: 0.0
Ponieważ ten problem zabawkowy korzysta tylko z dwóch kubitów, możemy to sprawdzić, używając solvera wartości własnych z algebry liniowej NumPy.
from numpy.linalg import eigvalsh
solution_eigenvalue = min(eigvalsh(observable_1.to_matrix()))
print(f"""Number of iterations: {result.nfev}""")
print(f"""Time (s): {execution_time}""")
print(
f"Percent error: {100*abs((result.fun - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Number of iterations: 103
Time (s): 0.4394676685333252
Percent error: 2.74e-08
Jak widać, wynik jest niezwykle bliski ideału.
Eksperymenty mające na celu poprawę szybkości i dokładności
Dodanie stanu referencyjnego
W poprzednim przykładzie nie użyliśmy żadnego operatora referencyjnego . Zastanówmy się teraz, jak można uzyskać idealny stan własny . Rozważmy następujący obwód.
from qiskit import QuantumCircuit
ideal_qc = QuantumCircuit(2)
ideal_qc.h(0)
ideal_qc.cx(0, 1)
ideal_qc.draw("mpl")

Możemy szybko sprawdzić, że ten obwód daje nam pożądany stan.
from qiskit.quantum_info import Statevector
Statevector(ideal_qc)
Statevector([0.70710678+0.j, 0. +0.j, 0. +0.j,
0.70710678+0.j],
dims=(2, 2))
Skoro zobaczyliśmy już, jak wygląda obwód przygotowujący stan rozwiązania, rozsądne wydaje się użycie bramki Hadamard jako obwodu referencyjnego, tak aby pełny ansatz przybrał postać:
reference = QuantumCircuit(2)
reference.h(0)
reference.cx(0, 1)
# Include barrier to separate reference from variational form
reference.barrier()
ref_ansatz = variational_form.decompose().compose(reference, front=True)
ref_ansatz.draw("mpl")
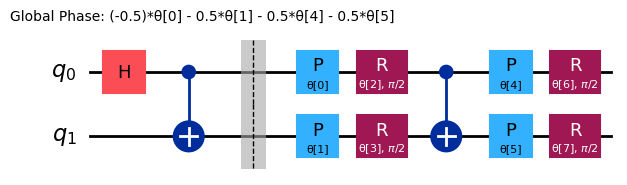
W tym nowym obwodzie idealne rozwiązanie można osiągnąć przy wszystkich parametrach ustawionych na , co potwierdza, że wybór obwodu referencyjnego jest rozsądny.
Porównajmy teraz liczbę ewaluacji funkcji kosztu, liczbę iteracji optymalizatora oraz czas potrzebny w porównaniu z poprzednią próbą.
import time
start_time = time.time()
ref_result = minimize(
cost_func_vqe, x0, args=(ref_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
Używając naszych optymalnych parametrów do obliczenia minimalnej wartości własnej:
experimental_min_eigenvalue_ref = cost_func_vqe(
ref_result.x, ref_ansatz, observable_1, estimator
)
print(experimental_min_eigenvalue_ref)
-5.999999996759607
print("ADDED REFERENCE STATE:")
print(f"""Number of iterations: {ref_result.nfev}""")
print(f"""Time (s): {execution_time}""")
print(
f"Percent error: {100*abs((experimental_min_eigenvalue_ref - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
ADDED REFERENCE STATE:
Number of iterations: 127
Time (s): 0.5620882511138916
Percent error: 5.40e-08
W zależności od konkretnego systemu może to skutkować poprawą szybkości lub dokładności w tym bardzo małym przykładzie lub nie. Chodzi o to, że rozpoczynanie od stanów referencyjnych uzasadnionych fizycznie staje się coraz ważniejsze dla poprawy szybkości i dokładności w miarę wzrostu skali problemów.
Zmiana punktu początkowego
Skoro widzieliśmy już efekt dodania stanu referencyjnego, przyjrzymy się temu, co się dzieje, gdy wybierzemy różne punkty początkowe . W szczególności użyjemy oraz .
Pamiętaj, że — zgodnie z tym, co omówiliśmy przy wprowadzaniu stanu referencyjnego — idealne rozwiązanie znalazłoby się, gdyby wszystkie parametry wynosiły , więc pierwszy punkt początkowy powinien dawać mniejszą liczbę ewaluacji.
import time
start_time = time.time()
x0 = [0, 0, 0, 0, 6, 0, 0, 0]
x0_1_result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
print("INITIAL POINT 1:")
print(f"""Number of iterations: {x0_1_result.nfev}""")
print(f"""Time (s): {execution_time}""")
INITIAL POINT 1:
Number of iterations: 108
Time (s): 0.4492197036743164
Dostosowanie punktu początkowego do :
import time
start_time = time.time()
x0 = 6 * np.ones(raw_ansatz.num_parameters)
x0_2_result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
print("INITIAL POINT 2:")
print(f"""Number of iterations: {x0_2_result.nfev}""")
print(f"""Time (s): {execution_time}""")
INITIAL POINT 2:
Number of iterations: 107
Time (s): 0.40889453887939453
Eksperymentując z różnymi punktami początkowymi, możesz osiągnąć zbieżność szybciej i przy mniejszej liczbie ewaluacji funkcji.
Eksperymentowanie z różnymi optymalizatorami
Możemy dostosować optymalizator za pomocą argumentu method funkcji minimize z SciPy; więcej opcji znajdziesz tutaj. Pierwotnie użyliśmy minimalizatora z ograniczeniami (COBYLA). W tym przykładzie zbadamy użycie minimalizatora bez ograniczeń (BFGS).
import time
start_time = time.time()
result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="BFGS"
)
end_time = time.time()
execution_time = end_time - start_time
print("CHANGED TO BFGS OPTIMIZER:")
print(f"""Number of iterations: {result.nfev}""")
print(f"""Time (s): {execution_time}""")
CHANGED TO BFGS OPTIMIZER:
Number of iterations: 117
Time (s): 0.31656408309936523
Przykład VQD
Tutaj jawnie wdrażamy framework wzorców Qiskit.
Krok 1: Odwzorowanie klasycznych danych wejściowych na problem kwantowy
Teraz zamiast szukać tylko najniższej wartości własnej naszych obserwabli, będziemy szukać wszystkich (gdzie ).
Przypomnijmy, że funkcje kosztu VQD to:
Jest to szczególnie istotne, ponieważ wektor (w tym przypadku ) musi zostać przekazany jako argument, gdy definiujemy obiekt VQD.
Ponadto w implementacji VQD w Qiskit, zamiast rozważać efektywne obserwable opisane w poprzednim notatniku, fidelity są obliczane bezpośrednio za pomocą algorytmu ComputeUncompute, który wykorzystuje prymityw Sampler do próbkowania prawdopodobieństwa uzyskania dla obwodu
. Działa to dokładnie dlatego, że to prawdopodobieństwo wynosi
ansatz = n_local(
num_qubits=2,
rotation_blocks=["ry", "rz"],
entanglement_blocks="cz",
# entanglement="linear",
reps=1,
)
ansatz.decompose().draw("mpl")
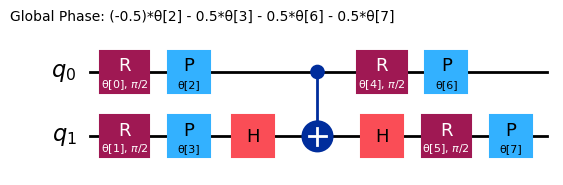
Zacznijmy od zbadania następującej obserwabli:
Ta obserwabla ma następujące wartości własne:
Oraz stany własne:
from qiskit.quantum_info import SparsePauliOp
observable_2 = SparsePauliOp.from_list([("II", 2), ("XX", -3), ("YY", 2), ("ZZ", -4)])
Będziemy używać poniższej funkcji do obliczania kary nakładania. Zauważ, że jest to wciąż część odwzorowania problemu na obwody kwantowe. Jednak, jak omówiono w poprzedniej lekcji, funkcja ta oblicza nakładanie się między bieżącym obwodem wariacyjnym a zoptymalizowanym obwodem z wcześniej uzyskanego stanu o niższej energii/koszcie. Nowo generowany obwód również musi być transpilowany, aby można go było uruchomić na rzeczywistym sprzęcie. Widzieliśmy już tę funkcję wcześniej, używaną na symulatorze. Tutaj musimy już uwzględnić transpilację i powiązaną optymalizację, gdy używamy rzeczywistego backendu, stąd linie wokół if realbackend == 1. To miesza trochę z krokiem 2, ale jawnie wywołamy krok 2 później.
import numpy as np
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
def calculate_overlaps(
ansatz, prev_circuits, parameters, sampler, realbackend, backend
):
def create_fidelity_circuit(circuit_1, circuit_2):
if len(circuit_1.clbits) > 0:
circuit_1.remove_final_measurements()
if len(circuit_2.clbits) > 0:
circuit_2.remove_final_measurements()
circuit = circuit_1.compose(circuit_2.inverse())
circuit.measure_all()
return circuit
overlaps = []
for prev_circuit in prev_circuits:
fidelity_circuit = create_fidelity_circuit(ansatz, prev_circuit)
if realbackend == 1:
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
fidelity_circuit = pm.run(fidelity_circuit)
sampler_job = sampler.run([(fidelity_circuit, parameters)])
meas_data = sampler_job.result()[0].data.meas
counts_0 = meas_data.get_int_counts().get(0, 0)
shots = meas_data.num_shots
overlap = counts_0 / shots
overlaps.append(overlap)
return np.array(overlaps)
Teraz dodajemy funkcję kosztu VQD. Zauważ, że w porównaniu z poprzednią lekcją mamy teraz dwa dodatkowe argumenty (realbackend i backend), które pomagają nam z transpilacją, gdy używamy rzeczywistych backendów.
def cost_func_vqd(
parameters,
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
hamiltonian,
realbackend,
backend,
):
estimator_job = estimator.run([(ansatz, hamiltonian, [parameters])])
total_cost = 0
if step > 1:
overlaps = calculate_overlaps(
ansatz, prev_states, parameters, sampler, realbackend, backend
)
total_cost = np.sum(
[np.real(betas[state] * overlap) for state, overlap in enumerate(overlaps)]
)
estimator_result = estimator_job.result()[0]
value = estimator_result.data.evs[0] + total_cost
return value
Ponownie wykorzystamy symulatory do debugowania, a następnie przejdziemy do prawdziwego sprzętu.
from qiskit.primitives import StatevectorSampler
from qiskit.primitives import StatevectorEstimator
sampler = StatevectorSampler(default_shots=4092)
estimator = StatevectorEstimator()
Tutaj wprowadzamy liczbę stanów, które chcemy obliczyć, kary oraz zbiór początkowych parametrów, x0.
from qiskit.quantum_info import SparsePauliOp
k = 4
betas = [50, 60, 40]
x0 = np.ones(8)
Przetestujemy teraz algorytm przy użyciu symulatorów:
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
observable_2,
realbackend,
None,
),
method="COBYLA",
options={"maxiter": 200, "tol": 0.000001},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -6.9999999999996
x: [ 1.571e+00 1.571e+00 2.519e+00 2.100e+00 1.242e+00
6.935e-01 2.298e+00 1.991e+00]
nfev: 151
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 3.698974255258432
x: [ 1.269e+00 1.109e+00 1.080e+00 1.200e+00 1.094e+00
1.163e+00 9.752e-01 9.519e-01]
nfev: 103
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 4.731320121938101
x: [ 1.533e+00 2.451e+00 2.526e+00 2.406e+00 1.968e+00
2.105e+00 8.537e-01 8.442e-01]
nfev: 110
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 7.008239313655201
x: [ 4.150e+00 2.120e+00 3.495e+00 7.262e-01 1.953e+00
-1.982e-01 3.263e-01 2.563e+00]
nfev: 126
maxcv: 0.0
eigenvalues
[np.float64(-6.9999999999996),
np.float64(3.698974255258432),
np.float64(4.731320121938101),
np.float64(7.008239313655201)]
Wyniki te są dość bliskie wartościom oczekiwanym, z dokładnością do błędu aproksymacji i fazy globalnej. Moglibyśmy dostosować tolerancję klasycznego optymalizatora i/lub kary za przekrywanie się wektorów stanu, aby uzyskać bardziej precyzyjne wartości.
solution_eigenvalues = [-7, 3, 5, 7]
for index, experimental_eigenvalue in enumerate(eigenvalues):
solution_eigenvalue = solution_eigenvalues[index]
print(
f"Percent error: {abs((experimental_eigenvalue - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Percent error: 5.71e-14
Percent error: 2.33e-01
Percent error: 5.37e-02
Percent error: 1.18e-03
Zmiana współczynników beta
Jak wspomniano w poprzedniej lekcji, wartości powinny być większe niż różnica między wartościami własnymi. Zobaczmy, co się stanie, gdy nie spełniają one tego warunku w przypadku
z wartościami własnymi
from qiskit.quantum_info import SparsePauliOp
k = 4
betas = np.ones(3)
x0 = np.zeros(8)
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
observable_2,
realbackend,
None,
),
method="COBYLA",
options={"tol": 0.01, "maxiter": 200},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -6.999916534745094
x: [ 1.568e+00 -1.569e+00 1.385e-01 1.398e-01 -7.972e-01
7.835e-01 -2.375e-01 4.539e-02]
nfev: 125
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -1.515139929812874
x: [-5.317e-04 -2.514e-03 1.016e+00 9.998e-01 3.890e-04
1.772e-04 1.568e-04 8.497e-04]
nfev: 35
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -0.509948114293115
x: [-3.796e-03 8.853e-03 3.015e-04 9.997e-01 6.271e-04
-2.554e-03 1.017e-04 2.766e-04]
nfev: 37
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 0.4914672235935682
x: [-7.178e-03 -8.652e-03 1.125e+00 -5.428e-02 -1.586e-03
2.031e-03 -3.462e-03 5.734e-03]
nfev: 35
maxcv: 0.0
solution_eigenvalues = [-7, 3, 5, 7]
for index, experimental_eigenvalue in enumerate(eigenvalues):
solution_eigenvalue = solution_eigenvalues[index]
print(
f"Percent error: {abs((experimental_eigenvalue - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Percent error: 1.19e-05
Percent error: 1.51e+00
Percent error: 1.10e+00
Percent error: 9.30e-01
Tym razem optymalizator zwraca ten sam stan jako proponowane rozwiązanie dla wszystkich stanów własnych: co jest oczywiście błędne. Dzieje się tak, ponieważ wartości beta były zbyt małe, aby ukarać minimalny stan własny w kolejnych funkcjach kosztu. W rezultacie nie został on wykluczony z efektywnej przestrzeni poszukiwań w późniejszych iteracjach algorytmu i zawsze był wybierany jako najlepsze możliwe rozwiązanie.
Zalecamy eksperymentowanie z wartościami i upewnianie się, że są one większe niż różnica między wartościami własnymi.
Krok 2: Optymalizacja problemu pod kątem wykonania kwantowego
Aby uruchomić to na rzeczywistym sprzęcie, musimy zoptymalizować obwody kwantowe dla naszego wybranego komputera kwantowego. Dla naszych celów użyjemy po prostu najmniej obciążonego backendu.
from qiskit_ibm_runtime import SamplerV2 as Sampler
from qiskit_ibm_runtime import EstimatorV2 as Estimator
from qiskit_ibm_runtime import Session, EstimatorOptions
from qiskit_ibm_runtime import QiskitRuntimeService
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
# Or use a specific backend
# backend = service.backend("ibm_brisbane")
print(backend)
<IBMBackend('ibm_brisbane')>
Przetranspilujemy nasz obwód za pomocą predefiniowanego menedżera przebiegów (pass manager) i poziomu optymalizacji 3.
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
isa_ansatz = pm.run(ansatz)
isa_observable = observable_2.apply_layout(layout=isa_ansatz.layout)
Krok 3: Wykonanie przy użyciu prymitywów Qiskit
Dbając o zresetowanie naszych wartości beta do wystarczająco wysokich wartości, możemy teraz uruchomić nasze obliczenia na rzeczywistym sprzęcie kwantowym.
# Estimated compute resource usage: 25 minutes.
# Benchmarked at 24 min, 30 sec on an Eagle r3 processor on 5-30-24
k = 2
betas = [30, 50, 80]
x0 = np.zeros(8)
real_prev_states = []
real_prev_opt_parameters = []
real_eigenvalues = []
realbackend = 1
estimator_options = EstimatorOptions(resilience_level=1, default_shots=10_000)
with Session(backend=backend) as session:
estimator = Estimator(mode=session, options=estimator_options)
sampler = Sampler(mode=session)
for step in range(1, k + 1):
if step > 1:
real_prev_states.append(isa_ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
isa_ansatz,
real_prev_states,
step,
betas,
estimator,
sampler,
isa_observable,
realbackend,
backend,
),
method="COBYLA",
options={"maxiter": 200},
)
print(result)
real_prev_opt_parameters = result.x
real_eigenvalues.append(result.fun)
session.close()
print(real_eigenvalues)
Krok 4: Post-processing, zwrócenie wyniku w formacie klasycznym
Nasz wynik jest strukturalnie podobny do tego, co zostało omówione w poprzednich lekcjach i przykładach. Jednak w powyższych wynikach jest coś problematycznego, z czego możemy wyciągnąć przestrogę w kontekście stanów wzbudzonych. Aby ograniczyć czas obliczeń wykorzystany w tym przykładzie dydaktycznym, ustawiliśmy maksymalną liczbę iteracji dla klasycznego optymalizatora, która była potencjalnie zbyt niska: 200 iteracji. Wcześniejsze obliczenia powyżej, na symulatorze, nie osiągnęły zbieżności w 200 iteracjach. Tutaj nasze osiągnęły zbieżność... ale z jaką tolerancją? Nie określiliśmy tolerancji, przy której COBYLA uznaje się za "zbieżny". Rzut oka na wartość funkcji i porównanie z poprzednimi uruchomieniami mówi nam, że COBYLA nie była blisko zbieżności z wymaganą przez nas precyzją.
Jest jeszcze jeden problem: energia pierwszego stanu wzbudzonego wydaje się być niższa niż energia stanu podstawowego! Zobacz, czy potrafisz wyjaśnić, jak to się mogło stać. Podpowiedź: wiąże się to z punktem zbieżności, o którym właśnie wspomnieliśmy. To zachowanie jest szczegółowo wyjaśnione poniżej, po zastosowaniu VQD do cząsteczki H2.
Chemia kwantowa: solver stanu podstawowego i energii wzbudzonej
Naszym celem jest zminimalizowanie wartości oczekiwanej obserwabli reprezentującej energię (Hamiltonian ):
from qiskit.quantum_info import SparsePauliOp
from qiskit.circuit.library import efficient_su2
H2_op = SparsePauliOp.from_list(
[
("II", -1.052373245772859),
("IZ", 0.39793742484318045),
("ZI", -0.39793742484318045),
("ZZ", -0.01128010425623538),
("XX", 0.18093119978423156),
]
)
chem_ansatz = efficient_su2(H2_op.num_qubits)
chem_ansatz.decompose().draw("mpl")
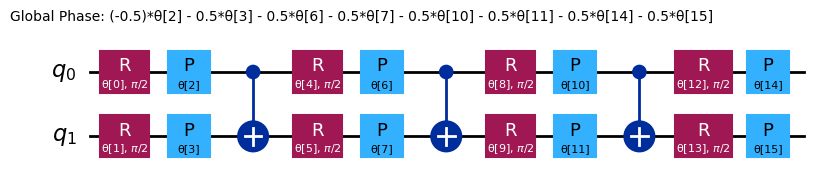
from qiskit import QuantumCircuit
def cost_func_vqe(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
# cost = estimator.run(ansatz, hamiltonian, parameter_values=params).result().values[0]
return cost
Teraz ustawiamy początkowy zestaw parametrów:
import numpy as np
x0 = np.ones(chem_ansatz.num_parameters)
Możemy zminimalizować tę funkcję kosztu, aby obliczyć optymalne parametry, a nasz kod możemy najpierw sprawdzić, korzystając z lokalnego symulatora.
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
# SciPy minimizer routine
from scipy.optimize import minimize
import time
start_time = time.time()
result = minimize(
cost_func_vqe, x0, args=(chem_ansatz, H2_op, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
result
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.857275029048451
x: [ 7.326e-01 1.354e+00 ... 1.040e+00 1.508e+00]
nfev: 242
maxcv: 0.0
Minimalna wartość funkcji kosztu (-1.857...) to energia stanu podstawowego cząsteczki H2, wyrażona w hartree.
Stany wzbudzone
Możemy również wykorzystać VQD do rozwiązania w sumie stanów (stanu podstawowego oraz pierwszego stanu wzbudzonego).
from qiskit.quantum_info import SparsePauliOp
import numpy as np
k = 2
betas = [33, 33]
# x0 = np.zeros(ansatz.num_parameters)
x0 = [
1.164e00,
-2.438e-01,
9.358e-04,
6.745e-02,
1.990e00,
9.810e-02,
6.154e-01,
5.454e-01,
]
Dodamy nasze obliczenie przekrywania:
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
H2_op,
realbackend,
None,
),
method="COBYLA",
options={"tol": 0.001, "maxiter": 2000},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.8572671093941977
x: [ 1.164e+00 -2.437e-01 2.118e-03 6.448e-02 1.990e+00
9.870e-02 6.167e-01 5.476e-01]
nfev: 58
maxcv: 0.0
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.0322873777662176
x: [ 3.205e+00 1.502e+00 1.699e+00 -1.107e-02 3.086e+00
1.530e+00 4.445e-02 7.013e-02]
nfev: 99
maxcv: 0.0
eigenvalues
[-1.8572671093941977, -1.0322873777662176]
Prawdziwy sprzęt i końcowe przestrogi
Aby uruchomić to na prawdziwym sprzęcie, musimy zoptymalizować obwody kwantowe pod kątem wybranego komputera kwantowego. Na nasze potrzeby użyjemy po prostu najmniej obciążonego backendu.
from qiskit_ibm_runtime import SamplerV2 as Sampler
from qiskit_ibm_runtime import EstimatorV2 as Estimator
from qiskit_ibm_runtime import Session, EstimatorOptions
from qiskit_ibm_runtime import QiskitRuntimeService
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
Do transpilacji użyjemy predefiniowanego pass managera i zmaksymalizujemy optymalizację naszego obwodu, stosując poziom optymalizacji 3.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
isa_ansatz = pm.run(ansatz)
isa_observable = H2_op.apply_layout(layout=isa_ansatz.layout)
Ponieważ VQD jest silnie iteracyjne, wykonamy wszystkie kroki wewnątrz sesji Runtime, tak aby nasze zadania były kolejkowane tylko na początku, a nie pomiędzy każdą aktualizacją parametrów. Nic innego nie zmienia się w składni funkcji kosztu ani estymatora.
x0 = [
1.306e00,
-2.284e-01,
6.913e-02,
-2.530e-02,
1.849e00,
7.433e-02,
6.366e-01,
5.600e-01,
]
# Estimated hardware usage: 20 min benchmarked on an Eagle r3 processor on 5-30-24
real_prev_states = []
real_prev_opt_parameters = []
real_eigenvalues = []
realbackend = 1
estimator_options = EstimatorOptions(resilience_level=1, default_shots=4096)
with Session(backend=backend) as session:
estimator = Estimator(mode=session)
sampler = Sampler(mode=session)
for step in range(1, k + 1):
if step > 1:
real_prev_states.append(
isa_ansatz.assign_parameters(real_prev_opt_parameters)
)
result = minimize(
cost_func_vqd,
x0,
args=(
isa_ansatz,
real_prev_states,
step,
betas,
estimator,
sampler,
isa_observable,
realbackend,
backend,
),
method="COBYLA",
options={"tol": 0.001, "maxiter": 300},
)
print(result)
real_prev_opt_parameters = result.x
real_eigenvalues.append(result.fun)
session.close()
print(real_eigenvalues)
Uzyskana energia stanu podstawowego (-1,83 hartree) nie jest zbyt daleka od poprawnej wartości (-1,85 hartree). Jednak energia stanu wzbudzonego jest znacznie odchylona. Przypomina to błędne zachowanie, które widzieliśmy wcześniej w tej lekcji. Energia raportowana dla stanu wzbudzonego jest niemal taka sama jak dla stanu podstawowego. W poprzednim przypadku widzieliśmy nawet energię stanu wzbudzonego, która była niższa niż raportowana energia stanu podstawowego.
Nie jest możliwe, by obliczenie wariacyjne dało energię niższą niż prawdziwa energia stanu podstawowego. W poprzednim przypadku uzyskana przez nas energia stanu podstawowego nie była zbyt bliska prawdziwemu stanowi podstawowemu. Ponieważ nie uzyskaliśmy wtedy prawdziwej energii stanu podstawowego, nie ma sprzeczności. W obecnym przypadku energia stanu podstawowego była dość bliska poprawnej wartości, a mimo to energia stanu wzbudzonego wydaje się dziwnie bliska tej samej wartości.
Aby lepiej zrozumieć, jak do tego doszło, przypomnijmy, że sposób, w jaki znajdujemy stan wzbudzony, polega na wymaganiu, aby stan wariacyjny był ortogonalny do stanu podstawowego (za pomocą obwodów overlap i wyrazów karnych). Jeśli nie uda nam się uzyskać dokładnej energii stanu podstawowego (lub jesteśmy oddaleni o kilka procent), to nie uda nam się także uzyskać dokładnego wektora stanu podstawowego! Tak więc, gdy wymagamy, aby stan wzbudzony był ortogonalny do pierwszego znalezionego przez nas stanu, nie narzucamy ortogonalności z prawdziwym stanem podstawowym, lecz z pewnym jego przybliżeniem (czasami słabym przybliżeniem). W rezultacie stan wzbudzony nie był zmuszony do ortogonalności z prawdziwym stanem podstawowym, a nasze oszacowania energii dla stanów wzbudzonych były w rzeczywistości dość bliskie energii stanu podstawowego.
Będzie to zawsze problem w VQD. Ale zasadniczo można to poprawić poprzez zwiększenie maksymalnej liczby iteracji klasycznego optymalizatora, narzucenie niższej tolerancji klasycznego optymalizatora i ewentualnie wypróbowanie innego ansatzu, jeśli zwykle pomijamy prawdziwy stan podstawowy. Jak widzieliśmy, może być również konieczne zmodyfikowanie kar za overlap (bety). Ale to tak naprawdę osobna kwestia. Żadna kara za overlap nie powstrzyma nas od prawdziwego stanu podstawowego, jeśli nie znaleźliśmy bardzo dobrego oszacowania prawdziwego stanu podstawowego dla obwodu overlap.
Optymalizacja: Max-Cut
Problem maksymalnego cięcia (Max-Cut) jest problemem optymalizacji kombinatorycznej, który polega na podziale wierzchołków grafu na dwa rozłączne zbiory w taki sposób, aby liczba krawędzi między tymi dwoma zbiorami była maksymalna. Bardziej formalnie, mając dany graf nieskierowany , gdzie to zbiór wierzchołków, a to zbiór krawędzi, problem Max-Cut wymaga podziału wierzchołków na dwa rozłączne podzbiory i tak, aby liczba krawędzi mających jeden koniec w , a drugi w , była maksymalna.
Możemy zastosować Max-Cut do rozwiązania różnych problemów, takich jak klasteryzacja, projektowanie sieci i przejścia fazowe. Zaczniemy od stworzenia grafu problemu:
import rustworkx as rx
from rustworkx.visualization import mpl_draw
n = 4
G = rx.PyGraph()
G.add_nodes_from(range(n))
# The edge syntax is (start, end, weight)
edges = [(0, 1, 1.0), (0, 2, 1.0), (0, 3, 1.0), (1, 2, 1.0), (2, 3, 1.0)]
G.add_edges_from(edges)
mpl_draw(
G, pos=rx.shell_layout(G), with_labels=True, edge_labels=str, node_color="#1192E8"
)

Ten problem można wyrazić jako problem optymalizacji binarnej. Dla każdego węzła , gdzie to liczba węzłów grafu (w tym przypadku ), rozważymy zmienną binarną . Zmienna ta przyjmie wartość , jeśli węzeł należy do jednej z grup, którą oznaczymy jako , oraz , jeśli należy do drugiej grupy, którą oznaczymy jako . Oznaczymy również przez (element macierzy sąsiedztwa ) wagę krawędzi prowadzącej od węzła do węzła . Ponieważ graf jest nieskierowany, . Następnie możemy sformułować nasz problem jako maksymalizację następującej funkcji kosztu:
Aby rozwiązać ten problem za pomocą komputera kwantowego, wyrazimy funkcję kosztu jako wartość oczekiwaną obserwabli. Jednakże obserwable, które Qiskit obsługuje natywnie, składają się z operatorów Pauli, które mają wartości własne i zamiast i . Dlatego dokonamy następującej zmiany zmiennej:
Gdzie . Możemy użyć macierzy sąsiedztwa , aby wygodnie uzyskać dostęp do wag wszystkich krawędzi. Zostanie to wykorzystane do uzyskania naszej funkcji kosztu:
Oznacza to, że:
Zatem nowa funkcja kosztu, którą chcemy maksymalizować, to:
Ponadto naturalną tendencją komputera kwantowego jest znajdowanie minimów (zazwyczaj najniższej energii) zamiast maksimów, więc zamiast maksymalizować będziemy minimalizować:
Teraz, gdy mamy funkcję kosztu do minimalizacji, której zmienne mogą przyjmować wartości i , możemy przeprowadzić następującą analogię z Pauli :
Innymi słowy, zmienna będzie równoważna bramce działającej na kubicie . Ponadto:
Wtedy obserwabla, którą będziemy rozważać, to:
do której będziemy musieli później dodać człon niezależny:
Operator jest kombinacją liniową wyrazów z operatorami Z na węzłach połączonych krawędzią (pamiętaj, że 0-ty kubit znajduje się najbardziej po prawej stronie): . Po skonstruowaniu operatora, ansatz dla algorytmu QAOA można łatwo zbudować, korzystając z obwodu QAOAAnsatz z biblioteki obwodów Qiskit.
from qiskit.circuit.library import QAOAAnsatz
from qiskit.quantum_info import SparsePauliOp
max_hamiltonian = SparsePauliOp.from_list(
[("IIZZ", 1), ("IZIZ", 1), ("IZZI", 1), ("ZIIZ", 1), ("ZZII", 1)]
)
max_ansatz = QAOAAnsatz(max_hamiltonian, reps=2)
# Draw
max_ansatz.decompose(reps=3).draw("mpl")

# Sum the weights, and divide by 2
offset = -sum(edge[2] for edge in edges) / 2
print(f"""Offset: {offset}""")
Offset: -2.5
def cost_func(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
# cost = estimator.run(ansatz, hamiltonian, parameter_values=params).result().values[0]
return cost
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
Ustawiamy teraz początkowy zestaw losowych parametrów:
import numpy as np
x0 = 2 * np.pi * np.random.rand(max_ansatz.num_parameters)
print(x0)
[6.0252949 0.58448176 2.15785731 1.13646074]
Do minimalizacji funkcji kosztu można użyć dowolnego optymalizatora klasycznego. Na rzeczywistym systemie kwantowym optymalizator zaprojektowany dla niegładkich krajobrazów funkcji kosztu zwykle radzi sobie lepiej. Tutaj używamy procedury COBYLA z SciPy za pośrednictwem funkcji minimize.
Ponieważ iteracyjnie wykonujemy wiele wywołań do Runtime, korzystamy z sesji, aby wykonać wszystkie wywołania w obrębie jednego bloku. Co więcej, dla QAOA rozwiązanie jest zakodowane w rozkładzie wyjściowym obwodu ansatz powiązanego z optymalnymi parametrami z minimalizacji. Dlatego będziemy potrzebować prymitywu Sampler i utworzymy jego instancję w tej samej sesji. Uruchamiamy naszą procedurę minimalizacji:
result = minimize(
cost_func, x0, args=(max_ansatz, max_hamiltonian, estimator), method="COBYLA"
)
print(result)
message: Optimization terminated successfully.
success: True
status: 1
fun: -2.585287311689236
x: [ 7.332e+00 3.904e-01 2.045e+00 1.028e+00]
nfev: 80
maxcv: 0.0
Wektor rozwiązania kątów parametrów (x), po podstawieniu do obwodu ansatz, daje poszukiwany przez nas podział grafu.
eigenvalue = cost_func(result.x, max_ansatz, max_hamiltonian, estimator)
print(f"""Eigenvalue: {eigenvalue}""")
print(f"""Max-Cut Objective: {eigenvalue + offset}""")
Eigenvalue: -2.585287311689236
Max-Cut Objective: -5.085287311689235
from qiskit.result import QuasiDistribution
from qiskit.primitives import StatevectorSampler
sampler = StatevectorSampler()
# Assign solution parameters to ansatz
qc = max_ansatz.assign_parameters(result.x)
# Add measurements to our circuit
qc.measure_all()
# Sample ansatz at optimal parameters
# samp_dist = sampler.run(qc).result().quasi_dists[0]
shots = 1024
job = sampler.run([qc], shots=shots)
qc.decompose().draw("mpl")

data_pub = job.result()[0].data
bitstrings = data_pub.meas.get_bitstrings()
counts = data_pub.meas.get_counts()
quasi_dist = QuasiDistribution(
{outcome: freq / shots for outcome, freq in counts.items()}
)
probabilities = quasi_dist
# Close the session since we are now done with it
# session.close()
from qiskit.visualization import plot_distribution
plot_distribution(counts)

binary_string = max(counts.items(), key=lambda kv: kv[1])[0]
x = np.asarray([int(y) for y in reversed(list(binary_string))])
colors = ["r" if x[i] == 0 else "c" for i in range(n)]
mpl_draw(
G, pos=rx.shell_layout(G), with_labels=True, edge_labels=str, node_color=colors
)

Podsumowanie
Dzięki tej lekcji nauczyłeś się:
- Jak napisać własny algorytm wariacyjny
- Jak zastosować algorytm wariacyjny do znajdowania minimalnych wartości własnych
- Jak wykorzystać algorytmy wariacyjne do rozwiązywania przypadków użycia w zastosowaniach
Przejdź do ostatniej lekcji, aby przystąpić do oceny i zdobyć odznakę!