Kodowanie danych
Wprowadzenie i notacja
Aby używać algorytmu kwantowego, dane klasyczne muszą zostać w jakiś sposób wprowadzone do obwodu kwantowego. Proces ten zazwyczaj nazywa się kodowaniem danych, ale bywa również określany jako ładowanie danych. Przypomnij sobie z poprzednich lekcji pojęcie mapowania cech — odwzorowania cech danych z jednej przestrzeni do drugiej. Samo przeniesienie danych klasycznych do komputera kwantowego jest pewnego rodzaju mapowaniem i może być nazwane mapowaniem cech. W praktyce wbudowane mapowania cech w Qiskit (takie jak z_feature_map i zz_feature_map) zazwyczaj obejmują warstwy rotacyjne i warstwy splątujące, które rozszerzają stan na wiele wymiarów w przestrzeni Hilberta. Proces kodowania jest krytyczną częścią algorytmów kwantowego uczenia maszynowego i bezpośrednio wpływa na ich możliwości obliczeniowe.
Niektóre z poniższych technik kodowania można efektywnie symulować klasycznie; jest to szczególnie łatwo zauważalne w metodach kodowania dających stany produktowe (to znaczy takie, które nie splątują kubitów). Pamiętaj też, że użyteczność kwantowa najprawdopodobniej leży tam, gdzie kwantowa złożoność zbioru danych jest dobrze dopasowana do metody kodowania. Jest więc bardzo prawdopodobne, że ostatecznie będziesz pisać własne obwody kodujące. Tutaj pokazujemy szeroki wybór możliwych strategii kodowania po prostu po to, abyś mógł je porównać i zobaczyć, co jest możliwe. Można sformułować kilka bardzo ogólnych stwierdzeń dotyczących użyteczności technik kodowania. Na przykład efficient_su2 (patrz poniżej) z pełnym schematem splątującym znacznie częściej uchwyci kwantowe cechy danych niż metody dające stany produktowe (jak z_feature_map). Nie oznacza to jednak, że efficient_su2 jest wystarczające lub wystarczająco dobrze dopasowane do Twojego zbioru danych, aby uzyskać przyspieszenie kwantowe. Wymaga to starannego rozważenia struktury modelowanych lub klasyfikowanych danych. Istnieje również pewne wyważenie z głębokością obwodu, ponieważ wiele mapowań cech, które w pełni splątują kubity w obwodzie, daje bardzo głębokie obwody — zbyt głębokie, aby uzyskać użyteczne wyniki na dzisiejszych komputerach kwantowych.
Notacja
Zbiór danych to zbiór wektorów danych: , gdzie każdy wektor jest -wymiarowy, to znaczy . Można to rozszerzyć na zespolone cechy danych. W tej lekcji możemy okazjonalnie używać tej notacji dla pełnego zbioru i jego konkretnych elementów, takich jak . Ale najczęściej będziemy odnosić się do ładowania pojedynczego wektora z naszego zbioru danych naraz i często będziemy po prostu odnosić się do pojedynczego wektora cech jako .
Dodatkowo, powszechnie używa się symbolu do oznaczenia mapowania cech wektora danych . W obliczeniach kwantowych w szczególności powszechnie odnosi się do mapowań w obliczeniach kwantowych za pomocą notacji, która podkreśla unitarny charakter tych operacji. Można by poprawnie używać tego samego symbolu dla obu; oba są mapowaniami cech. W tym kursie zazwyczaj używamy:
- , omawiając mapowania cech w uczeniu maszynowym ogólnie, oraz
- , omawiając implementacje obwodowe mapowań cech.
Normalizacja i utrata informacji
W klasycznym uczeniu maszynowym cechy danych treningowych są często „normalizowane” lub przeskalowywane, co często poprawia wydajność modelu. Jednym z częstych sposobów jest użycie normalizacji min-max lub standaryzacji. W normalizacji min-max kolumny cech macierzy danych (powiedzmy cecha ) są normalizowane:
gdzie min i max odnoszą się do minimum i maksimum cechy po wektorach danych w zbiorze . Wszystkie wartości cech znajdują się wtedy w przedziale jednostkowym: dla wszystkich , .
Normalizacja jest również fundamentalnym pojęciem w mechanice kwantowej i obliczeniach kwantowych, ale nieco różni się od normalizacji min-max. Normalizacja w mechanice kwantowej wymaga, aby długość (w kontekście obliczeń kwantowych — norma 2) wektora stanu była równa jedności: , co zapewnia, że prawdopodobieństwa pomiarów sumują się do 1. Stan jest normalizowany przez podzielenie przez normę 2; to znaczy przez przeskalowanie
W obliczeniach kwantowych i mechanice kwantowej nie jest to normalizacja narzucana przez ludzi na dane, lecz fundamentalna własność stanów kwantowych. W zależności od schematu kodowania, to ograniczenie może wpływać na sposób przeskalowania danych. Na przykład w kodowaniu amplitudowym (patrz poniżej) wektor danych jest normalizowany , zgodnie z wymogiem mechaniki kwantowej, i wpływa to na skalowanie kodowanych danych. W kodowaniu fazowym zaleca się przeskalowanie wartości cech tak, aby , aby nie wystąpiła utrata informacji z powodu efektu modulo kodowania do kąta fazy kubitu[1,2].
Metody kodowania
W kolejnych kilku sekcjach będziemy odnosić się do małego przykładowego klasycznego zbioru danych składającego się z wektorów danych, z których każdy ma cechy:
We wprowadzonej powyżej notacji moglibyśmy powiedzieć, że cecha wektora danych w naszym zbiorze to na przykład.
Kodowanie bazowe
Kodowanie bazowe koduje klasyczny ciąg -bitowy do stanu bazowego obliczeniowego systemu -kubitowego. Weźmy na przykład Można to przedstawić jako ciąg -bitowy jako , a przez system -kubitowy jako stan kwantowy . Bardziej ogólnie, dla ciągu -bitowego: , odpowiadający stan -kubitowy to z dla . Zwróć uwagę, że dotyczy to tylko pojedynczej cechy.
Kodowanie bazowe w obliczeniach kwantowych reprezentuje każdy klasyczny bit jako osobny kubit, mapując binarną reprezentację danych bezpośrednio na stany kwantowe w bazie obliczeniowej. Gdy trzeba zakodować wiele cech, każda cecha jest najpierw konwertowana na postać binarną, a następnie przypisywana do odrębnej grupy kubitów — jednej grupy na cechę — gdzie każdy kubit odzwierciedla bit w binarnej reprezentacji tej cechy.
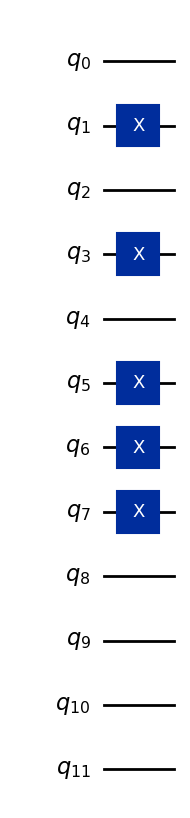
Jako przykład, zakodujmy wektor (5, 7, 0).
Załóżmy, że wszystkie cechy są przechowywane w czterech bitach (więcej niż potrzebujemy, ale wystarczająco, aby reprezentować dowolną liczbę całkowitą jednocyfrową w bazie 10):
5 → binarnie 0101
7 → binarnie 0111
0 → binarnie 0000
Te ciągi bitów są przypisane do trzech zestawów po cztery kubity, więc ogólny 12-kubitowy stan bazowy to:
Tutaj pierwsze cztery kubity reprezentują pierwszą cechę, kolejne cztery kubity drugą cechę, a ostatnie cztery kubity trzecią cechę. Poniższy kod konwertuje wektor danych (5,7,0) na stan kwantowy i jest uogólniony, aby zrobić to dla innych jednocyfrowych cech.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit
from qiskit import QuantumCircuit
# Data point to encode
x = 5 # binary: 0101
y = 7 # binary: 0111
z = 0 # binary: 0000
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, "04b")] # [0,1,0,1]
y_bits = [int(b) for b in format(y, "04b")] # [0,1,1,1]
z_bits = [int(b) for b in format(z, "04b")] # [0,0,0,0]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,1,0,1,1,1,0,0,0,0]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw("mpl")
Sprawdź swoje zrozumienie
Przeczytaj poniższe pytanie, zastanów się nad odpowiedzią, a następnie kliknij trójkąt, aby ujawnić rozwiązanie.
Napisz kod, aby zakodować pierwszy wektor w naszym przykładowym zbiorze danych :
używając kodowania bazowego.
Odpowiedź:
import math
from qiskit import QuantumCircuit
# Data point to encode
x = 4 # binary: 0100
y = 8 # binary: 1000
z = 5 # binary: 0101
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, '04b')] # [0,1,0,0]
y_bits = [int(b) for b in format(y, '04b')] # [1,0,0,0]
z_bits = [int(b) for b in format(z, '04b')] # [0,1,0,1]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,0,1,0,0,0,0,1,0,1]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw('mpl')
Kodowanie amplitudowe
Kodowanie amplitudowe koduje dane w amplitudach stanu kwantowego. Reprezentuje znormalizowany klasyczny -wymiarowy wektor danych jako amplitudy -kubitowego stanu kwantowego :
gdzie jest tym samym wymiarem wektorów danych jak wcześniej, jest elementem , a jest stanem bazowym obliczeniowym. Tutaj jest stałą normalizacyjną, którą należy wyznaczyć z kodowanych danych. Jest to warunek normalizacji narzucony przez mechanikę kwantową:
Ogólnie rzecz biorąc, jest to warunek inny niż normalizacja min/max stosowana dla każdej cechy we wszystkich wektorach danych. Dokładnie to, jak to zostanie rozwiązane, zależy od Twojego problemu. Ale nie da się obejść powyższego warunku normalizacji mechaniki kwantowej.
W kodowaniu amplitudowym każda cecha w wektorze danych jest przechowywana jako amplituda innego stanu kwantowego. Ponieważ system kubitów dostarcza amplitud, kodowanie amplitudowe cech wymaga kubitów.
Jako przykład, zakodujmy pierwszy wektor z naszego przykładowego zbioru danych , , używając kodowania amplitudowego. Normalizując otrzymany wektor, otrzymujemy:
a wynikowy 2-kubitowy stan kwantowy będzie miał postać:
W powyższym przykładzie liczba cech w wektorze nie jest potęgą liczby 2. Gdy nie jest potęgą liczby 2, po prostu wybieramy taką wartość liczby kubitów , aby , i uzupełniamy wektor amplitud nieinformatywnymi stałymi (tutaj zerami).
Podobnie jak w kodowaniu bazowym, po obliczeniu, jaki stan zakoduje nasz zbiór danych, w Qiskit możemy użyć funkcji initialize, aby go przygotować:
import math
desired_state = [
1 / math.sqrt(105) * 4,
1 / math.sqrt(105) * 8,
1 / math.sqrt(105) * 5,
1 / math.sqrt(105) * 0,
]
qc = QuantumCircuit(2)
qc.initialize(desired_state, [0, 1])
qc.decompose(reps=5).draw(output="mpl")

Zaletą kodowania amplitudowego jest wspomniany wymóg użycia jedynie kubitów do zakodowania. Jednak kolejne algorytmy muszą operować na amplitudach stanu kwantowego, a metody przygotowywania i mierzenia stanów kwantowych zwykle nie są efektywne.
Sprawdź swoje zrozumienie
Przeczytaj poniższe pytania, zastanów się nad odpowiedziami, a następnie kliknij trójkąty, aby zobaczyć rozwiązania.
Zapisz znormalizowany stan kodujący następujący wektor (złożony z dwóch wektorów z naszego przykładowego zbioru danych):
przy użyciu kodowania amplitudowego.
Odpowiedź:
Aby zakodować 6 liczb, będziemy potrzebować co najmniej 6 dostępnych stanów, na których amplitudach możemy je zakodować. To będzie wymagało 3 kubitów. Używając nieznanego współczynnika normalizacji , możemy to zapisać jako:
Zauważ, że
Ostatecznie więc,
Dla tego samego wektora danych napisz kod tworzący obwód, który ładuje te cechy danych za pomocą kodowania amplitudowego.
Odpowiedź:
desired_state = [
9 / math.sqrt(270),
8 / math.sqrt(270),
6 / math.sqrt(270),
2 / math.sqrt(270),
9 / math.sqrt(270),
2 / math.sqrt(270),
0,
0,
]
print(desired_state)
qc = QuantumCircuit(3)
qc.initialize(desired_state, [0, 1, 2])
qc.decompose(reps=8).draw(output="mpl")
[0.5477225575051662, 0.48686449556014766, 0.36514837167011077, 0.12171612389003691, 0.5477225575051662, 0.12171612389003691, 0, 0]

Może się zdarzyć, że będziesz mieć do czynienia z bardzo dużymi wektorami danych. Rozważ wektor
Napisz kod automatyzujący normalizację i wygeneruj obwód kwantowy do kodowania amplitudowego.
Odpowiedź:
Istnieje wiele możliwych odpowiedzi. Oto kod, który wypisuje kilka kroków po drodze:
import numpy as np
from math import sqrt
init_list = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5]
qubits = round(np.log(len(init_list)) / np.log(2) + 0.4999999999)
need_length = 2**qubits
pad = need_length - len(init_list)
for i in range(0, pad):
init_list.append(0)
init_array = np.array(init_list) # Unnormalized data vector
length = sqrt(
sum(init_array[i] ** 2 for i in range(0, len(init_array)))
) # Vector length
norm_array = init_array / length # Normalized array
print("Normalized array:")
print(norm_array)
print()
qubit_numbers = []
for i in range(0, qubits):
qubit_numbers.append(i)
print(qubit_numbers)
qc = QuantumCircuit(qubits)
qc.initialize(norm_array, qubit_numbers)
qc.decompose(reps=7).draw(output="mpl")
Normalized array: [0.17342199 0.34684399 0.21677749 0.39019949 0.34684399 0.26013299 0.086711 0.39019949 0.086711 0.21677749 0.30348849 0. 0.1300665 0.30348849 0.21677749 0. ]
[0, 1, 2, 3]
Czy widzisz zalety kodowania amplitudowego nad kodowaniem bazowym? Jeśli tak, wyjaśnij.
Odpowiedź:
Może istnieć kilka odpowiedzi. Jedna z nich brzmi, że przy ustalonym uporządkowaniu stanów bazowych kodowanie amplitudowe zachowuje kolejność kodowanych liczb. Często będzie ono także kodowane w sposób gęstszy.
Zaletą kodowania amplitudowego jest to, że dla -wymiarowego wektora danych (o cechach) wymagane jest jedynie kubitów. Jednak kodowanie amplitudowe jest zazwyczaj nieefektywną procedurą, która wymaga przygotowania dowolnego stanu, co jest wykładnicze względem liczby bramek CNOT. Ujmując to inaczej, przygotowanie stanu ma wielomianową złożoność czasową względem liczby wymiarów, gdzie , a to liczba kubitów. Kodowanie amplitudowe „zapewnia wykładnicze oszczędności w przestrzeni kosztem wykładniczego wzrostu czasu”[3]; jednak w pewnych przypadkach osiągalne są wzrosty czasu wykonania do [4]. Dla uzyskania pełnego kwantowego przyspieszenia od początku do końca, należy wziąć pod uwagę złożoność czasową ładowania danych.
Kodowanie kątowe
Kodowanie kątowe jest interesujące w wielu modelach QML wykorzystujących mapy cech Pauliego, takich jak kwantowe maszyny wektorów nośnych (QSVM) i wariacyjne obwody kwantowe (VQC), między innymi. Kodowanie kątowe jest ściśle związane z kodowaniem fazowym oraz gęstym kodowaniem kątowym, które zostaną przedstawione poniżej. Tutaj użyjemy określenia „kodowanie kątowe” w odniesieniu do obrotu o , czyli obrotu odbiegającego od osi , realizowanego na przykład przez bramkę lub [1,3]. W rzeczywistości dane można zakodować w dowolnym obrocie lub kombinacji obrotów. Jednak jest powszechny w literaturze, dlatego kładziemy na niego nacisk.
Zastosowane do pojedynczego kubita, kodowanie kątowe nadaje obrót wokół osi Y proporcjonalny do wartości danej. Rozważmy kodowanie pojedynczej (-tej) cechy z -tego wektora danych w zbiorze danych, :
Alternatywnie, kodowanie kątowe można zrealizować przy użyciu bramek , choć zakodowany stan miałby zespoloną fazę względną w porównaniu z .
Kodowanie kątowe różni się od dwóch poprzednio omawianych metod pod kilkoma względami. W kodowaniu kątowym:
- Każda wartość cechy jest odwzorowywana na odpowiadający jej kubit, , pozostawiając kubity w stanie iloczynowym.
- Jedna wartość liczbowa jest kodowana naraz, a nie cały zbiór cech z punktu danych.
- kubitów jest wymaganych dla cech danych, gdzie . Często zachodzi równość. W kolejnych sekcjach zobaczymy, w jaki sposób możliwe jest .
- Wynikowy obwód ma stałą głębokość (zazwyczaj głębokość wynosi 1 przed transpilacją).
Kwantowy obwód o stałej głębokości sprawia, że metoda ta jest szczególnie odpowiednia dla obecnego sprzętu kwantowego. Dodatkową cechą kodowania naszych danych za pomocą (a konkretnie naszego wyboru kodowania kątowego wokół osi Y) jest to, że tworzy ono stany kwantowe o wartościach rzeczywistych, które mogą być przydatne w niektórych zastosowaniach. W przypadku rotacji wokół osi Y dane są odwzorowywane za pomocą bramki rotacji wokół osi Y o rzeczywistym kącie (Qiskit RYGate). Podobnie jak w przypadku kodowania fazowego (patrz poniżej), zalecamy przeskalowanie danych tak, aby , co zapobiega utracie informacji i innym niepożądanym efektom.
Poniższy kod Qiskit obraca pojedynczy kubit z początkowego stanu w celu zakodowania wartości danych .
from qiskit.quantum_info import Statevector
from math import pi
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
Zdefiniujemy funkcję służącą do wizualizacji działania na wektorze stanu. Szczegóły definicji funkcji nie są istotne, ale możliwość wizualizacji wektorów stanu i ich zmian jest ważna.
import numpy as np
from qiskit.visualization.bloch import Bloch
from qiskit.visualization.state_visualization import _bloch_multivector_data
def plot_Nstates(states, axis, plot_trace_points=True):
"""This function plots N states to 1 Bloch sphere"""
bloch_vecs = [_bloch_multivector_data(s)[0] for s in states]
if axis is None:
bloch_plot = Bloch()
else:
bloch_plot = Bloch(axes=axis)
bloch_plot.add_vectors(bloch_vecs)
if len(states) > 1:
def rgba_map(x, num):
g = (0.95 - 0.05) / (num - 1)
i = 0.95 - g * num
y = g * x + i
return (0.0, y, 0.0, 0.7)
num = len(states)
bloch_plot.vector_color = [rgba_map(x, num) for x in range(1, num + 1)]
bloch_plot.vector_width = 3
bloch_plot.vector_style = "simple"
if plot_trace_points:
def trace_points(bloch_vec1, bloch_vec2):
# bloch_vec = (x,y,z)
n_points = 15
thetas = np.arccos([bloch_vec1[2], bloch_vec2[2]])
phis = np.arctan2(
[bloch_vec1[1], bloch_vec2[1]], [bloch_vec1[0], bloch_vec2[0]]
)
if phis[1] < 0:
phis[1] = phis[1] + 2 * pi
angles0 = np.linspace(phis[0], phis[1], n_points)
angles1 = np.linspace(thetas[0], thetas[1], n_points)
xp = np.cos(angles0) * np.sin(angles1)
yp = np.sin(angles0) * np.sin(angles1)
zp = np.cos(angles1)
pnts = [xp, yp, zp]
bloch_plot.add_points(pnts)
bloch_plot.point_color = "k"
bloch_plot.point_size = [4] * len(bloch_plot.points)
bloch_plot.point_marker = ["o"]
for i in range(len(bloch_vecs) - 1):
trace_points(bloch_vecs[i], bloch_vecs[i + 1])
bloch_plot.sphere_alpha = 0.05
bloch_plot.frame_alpha = 0.15
bloch_plot.figsize = [4, 4]
bloch_plot.render()
plot_Nstates(states, axis=None, plot_trace_points=True)

To była tylko pojedyncza cecha pojedynczego wektora danych. Kodując cech w kątach rotacji kubitów, powiedzmy dla wektora danych zakodowany stan iloczynowy będzie wyglądał następująco:
Zauważmy, że jest to równoważne
Sprawdź swoje zrozumienie
Przeczytaj poniższe pytania, zastanów się nad odpowiedziami, a następnie kliknij trójkąty, aby odsłonić rozwiązania.
Zakoduj wektor danych przy użyciu kodowania kątowego, jak opisano powyżej.
Odpowiedź:
qc = QuantumCircuit(3)
qc.ry(0, 0)
qc.ry(2 * math.pi / 4, 1)
qc.ry(2 * math.pi / 2, 2)
qc.draw(output="mpl")

Używając kodowania kątowego opisanego powyżej, ile kubitów jest potrzebnych do zakodowania 5 cech?
Odpowiedź: 5
Kodowanie fazowe
Kodowanie fazowe jest bardzo podobne do opisanego powyżej kodowania kątowego. Kąt fazowy kubitu to rzeczywisty kąt wokół osi mierzony od osi +. Dane są odwzorowywane za pomocą rotacji fazowej, , gdzie (więcej informacji w Qiskit PhaseGate). Zaleca się przeskalowanie danych tak, aby . Zapobiega to utracie informacji i innym potencjalnie niepożądanym efektom[1,2].
Kubit jest często inicjalizowany w stanie , który jest stanem własnym operatora rotacji fazowej, co oznacza, że stan kubitu najpierw musi zostać obrócony, aby można było zaimplementować kodowanie fazowe. Dlatego sensowne jest zainicjowanie stanu za pomocą bramki Hadamard: . Kodowanie fazowe na pojedynczym kubicie oznacza nadanie fazy względnej proporcjonalnej do wartości danych:
Procedura kodowania fazowego odwzorowuje każdą wartość cechy na fazę odpowiadającego jej kubitu, . W sumie kodowanie fazowe ma głębokość obwodu równą 2, wliczając warstwę Hadamarda, co czyni je wydajnym schematem kodowania. Zakodowany fazowo stan wielokubitowy ( kubitów dla cech) jest stanem iloczynowym:
Poniższy kod Qiskit najpierw przygotowuje stan początkowy pojedynczego kubitu, obracając go bramką Hadamard, a następnie obraca go ponownie za pomocą bramki fazowej w celu zakodowania cechy danych .
qc = QuantumCircuit(1)
qc.h(0) # Hadamard gate rotates state down to Bloch equator
state1 = Statevector.from_instruction(qc)
qc.p(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
qc.draw("mpl", scale=1)

Możemy zwizualizować rotację w przy użyciu zdefiniowanej przez nas funkcji plot_Nstates.
plot_Nstates(states, axis=None, plot_trace_points=True)

Wykres sfery Blocha przedstawia obrót wokół osi Z , gdzie . Jasnozielona strzałka wskazuje stan końcowy.
Kodowanie fazowe jest używane w wielu kwantowych mapach cech, w szczególności w mapach cech i , a także w ogólnych mapach cech Pauliego i innych.
Sprawdź swoje zrozumienie
Przeczytaj poniższe pytania, zastanów się nad odpowiedziami, a następnie kliknij trójkąty, aby odsłonić rozwiązania.
Ile kubitów jest wymaganych, aby przy użyciu kodowania fazowego opisanego powyżej zapisać 8 cech?
Odpowiedź: 8
Napisz kod, aby zakodować wektor przy użyciu kodowania fazowego.
Odpowiedź:
Może istnieć wiele odpowiedzi. Oto jeden przykład:
phase_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0]
qc = QuantumCircuit(len(phase_data))
for i in range(0, len(phase_data)):
qc.h(i)
qc.rz(phase_data[i] * 2 * math.pi / float(max(phase_data)), i)
qc.draw(output="mpl")

Gęste kodowanie kątowe
Gęste kodowanie kątowe (DAE) jest połączeniem kodowania kątowego i kodowania fazowego. DAE pozwala na zakodowanie dwóch wartości cech w jednym kubicie: jednej cechy jako kąta obrotu wokół osi Y, a drugiej jako kąta obrotu wokół osi : . Dwie cechy są kodowane następująco:
Zakodowanie dwóch cech danych w jednym kubicie skutkuje redukcją liczby kubitów wymaganych do kodowania. Rozszerzając to na więcej cech, wektor danych można zakodować jako:
DAE można uogólnić na dowolne funkcje dwóch cech zamiast użytych tutaj funkcji sinusoidalnych. Nazywa się to ogólnym kodowaniem kubitowym[7].
Jako przykład DAE, poniższy kod koduje i wizualizuje zakodowanie cech i .
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(3 * pi / 8, 0)
state2 = Statevector.from_instruction(qc)
qc.rz(7 * pi / 4, 0)
state3 = Statevector.from_instruction(qc)
states = state1, state2, state3
plot_Nstates(states, axis=None, plot_trace_points=True)

Sprawdź swoje zrozumienie
Przeczytaj poniższe pytania, zastanów się nad odpowiedziami, a następnie kliknij trójkąty, aby odsłonić rozwiązania.
Biorąc pod uwagę powyższe omówienie, ile kubitów potrzeba do zakodowania 6 cech przy użyciu gęstego kodowania?
Odpowiedź: 3
Napisz kod, aby załadować wektor przy użyciu gęstego kodowania kątowego.
Odpowiedź:
Zauważ, że uzupełniliśmy listę zerem ("0"), aby uniknąć problemu pojedynczego nieużywanego parametru w naszym schemacie kodowania.
dense_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5, 0]
qc = QuantumCircuit(int(len(dense_data) / 2))
entry = 0
for i in range(0, int(len(dense_data) / 2)):
qc.ry(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.rz(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.draw(output="mpl")

Kodowanie z wbudowanymi mapami cech
Kodowanie w dowolnych punktach
Kodowanie kątowe, kodowanie fazowe i kodowanie gęste przygotowywały stany iloczynowe z cechą zakodowaną na każdym kubicie (lub dwiema cechami na kubit). Różni się to od kodowania bazowego i kodowania amplitudowego tym, że te metody korzystają ze stanów splątanych. Nie istnieje odpowiedniość 1:1 między cechą danych a kubitem. Na przykład w kodowaniu amplitudowym jedna cecha może być amplitudą stanu , a inna cecha amplitudą stanu . Ogólnie rzecz biorąc, metody kodujące w stanach iloczynowych dają płytsze obwody i mogą przechowywać 1 lub 2 cechy na każdym kubicie. Metody wykorzystujące splątanie i wiążące cechę ze stanem, a nie z kubitem, skutkują głębszymi obwodami i mogą średnio przechowywać więcej cech na kubit.
Jednakże kodowanie nie musi odbywać się wyłącznie w stanach iloczynowych lub wyłącznie w stanach splątanych, jak w kodowaniu amplitudowym. Istotnie, wiele schematów kodowania wbudowanych w Qiskit pozwala na kodowanie zarówno przed, jak i po warstwie splątania, w przeciwieństwie do kodowania tylko na początku. Jest to znane jako "ponowne wczytywanie danych" (data reuploading). Powiązane prace znajdują się w odnośnikach [5] i [6].
W tej sekcji użyjemy i zwizualizujemy kilka wbudowanych schematów kodowania. Wszystkie metody w tej sekcji kodują cech jako obroty na sparametryzowanych bramkach na kubitach, gdzie . Należy zauważyć, że maksymalizacja ładowania danych dla danej liczby kubitów nie jest jedynym kryterium. W wielu przypadkach głębokość obwodu może być jeszcze ważniejszym kryterium niż liczba kubitów.
Efficient SU2
Powszechnym i użytecznym przykładem kodowania ze splątaniem jest obwód efficient_su2 z Qiskit. Co imponujące, ten obwód może na przykład zakodować 8 cech na zaledwie 2 kubitach. Zobaczmy to, a następnie spróbujmy zrozumieć, jak jest to możliwe.
from qiskit.circuit.library import efficient_su2
circuit = efficient_su2(num_qubits=2, reps=1, insert_barriers=True)
circuit.decompose().draw(output="mpl")

Zapisując nasz stan, będziemy używać konwencji Qiskit, zgodnie z którą najmniej znaczące kubity są uporządkowane po prawej stronie, jak w lub Takie stany mogą bardzo szybko stać się bardzo skomplikowane i ten rzadki przykład może pomóc wyjaśnić, dlaczego takie stany rzadko są zapisywane w jawnej postaci.
Nasz układ zaczyna się w stanie Do pierwszej bariery (punktu, który oznaczamy ), nasze stany to:
To po prostu gęste kodowanie, które widzieliśmy wcześniej. Teraz, po bramce CNOT, przy drugiej barierze (), nasz stan to
Teraz stosujemy ostatni zestaw obrotów jednokubitowych i zbieramy podobne stany, aby uzyskać:
Prawdopodobnie jest to zbyt skomplikowane, aby je rozszyfrować. Zamiast tego zróbmy krok w tył i zastanówmy się, ile parametrów załadowaliśmy do stanu: osiem. Ale mamy tylko cztery stany bazy obliczeniowej. Na pierwszy rzut oka może się wydawać, że załadowaliśmy więcej parametrów, niż ma to sens, ponieważ stan końcowy można zapisać jako . Zauważ jednak, że każdy współczynnik jest zespolony! Zapisane w ten sposób:
Widać, że rzeczywiście mamy osiem parametrów w stanie, na którym możemy zakodować nasze osiem cech.
Zwiększając liczbę kubitów i zwiększając liczbę powtórzeń warstw splatających i obrotowych, można zakodować znacznie więcej danych. Zapisywanie funkcji falowych szybko staje się niewykonalne. Możemy jednak nadal obserwować kodowanie w działaniu.
Tutaj kodujemy wektor danych z 12 cechami, na 3-kubitowym obwodzie efficient_su2, wykorzystując każdą z parametryzowanych bramek do zakodowania innej cechy.
W tym wektorze danych cechy są pokazane w określonej kolejności. W izolacji nie ma znaczenia, czy są one zakodowane w tej kolejności, czy w odwrotnej. Ważne jest, aby to śledzić i być konsekwentnym. Zauważ na diagramie obwodu, że efficient_su2 zakłada pewne uporządkowanie kodowania, konkretnie wypełnianie pierwszej warstwy parametryzowanych bramek od kubitu 0 do kubitu 2, a następnie przejście do kolejnej warstwy. Nie jest to ani zgodne, ani niezgodne z notacją little-endian, ponieważ w tym przypadku cechy danych nie mogą być uporządkowane według kubitów a priori, zanim nie zostanie określony obwód kodujący.
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2]
circuit = efficient_su2(num_qubits=3, reps=1, insert_barriers=True)
encode = circuit.assign_parameters(x)
encode.decompose().draw(output="mpl")

Zamiast zwiększać liczbę kubitów, możesz zdecydować się na zwiększenie liczby powtórzeń warstw splatających i obrotowych. Istnieją jednak ograniczenia co do tego, jak wiele powtórzeń jest użytecznych. Jak już wcześniej stwierdzono, istnieje kompromis: obwody z większą liczbą kubitów lub większą liczbą powtórzeń warstw splatających i obrotowych mogą przechowywać więcej parametrów, ale kosztem większej głębokości obwodu. Wrócimy poniżej do głębokości niektórych wbudowanych map cech. Kilka kolejnych metod kodowania wbudowanych w Qiskit ma "mapę cech" (feature map) jako część swoich nazw. Powtórzmy, że kodowanie danych w obwód kwantowy jest mapowaniem cech, w tym sensie, że przenosi dane do nowej przestrzeni: przestrzeni Hilberta zaangażowanych kubitów. Zależność między wymiarowością pierwotnej przestrzeni cech a wymiarowością przestrzeni Hilberta zależy od obwodu użytego do kodowania.
Mapa cech
Mapa cech (ZFM) może być interpretowana jako naturalne rozszerzenie kodowania fazowego. ZFM składa się z naprzemiennych warstw bramek jednokubitowych: warstw bramek Hadamard i warstw bramek fazowych. Niech wektor danych ma cech. Obwód kwantowy realizujący mapowanie cech jest reprezentowany jako operator unitarny działający na stan początkowy:
gdzie jest -kubitowym stanem podstawowym. Notacja ta jest używana dla spójności z odniesieniem [4] Havlicek et al. Cechy danych są mapowane jeden do jednego z odpowiadającymi im kubitami. Na przykład, jeśli masz 8 cech w wektorze danych, to użyjesz 8 kubitów. Obwód ZFM składa się z powtórzeń podobwodu złożonego z warstw bramek Hadamard i warstw bramek fazowych. Warstwa Hadamarda składa się z bramki Hadamard działającej na każdym kubicie w rejestrze -kubitowym, , w ramach tego samego etapu algorytmu. Opis ten stosuje się również do warstwy bramek fazowych, w której na kubit działa . Każda bramka ma jedną cechę jako argument, ale warstwa bramek fazowych ( jest funkcją wektora danych. Pełny unitarny obwód ZFM z pojedynczym powtórzeniem to:
Wtedy powtórzeń tej operacji unitarnej to
Cechy danych, , są mapowane na bramki fazowe w ten sam sposób we wszystkich powtórzeniach. Stan mapy cech ZFM jest stanem produktowym i jest efektywny dla symulacji klasycznej[4].
Na początek, jako mały przykład, dwukubitowy obwód ZFM jest zakodowany przy użyciu Qiskit i narysowany, aby pokazać prostą strukturę obwodu. W tym przykładzie, pojedyncze powtórzenie, , jest zaimplementowane z wektorem danych . Zauważ, że jest to zapisane w standardowej kolejności wektora w Pythonie, co oznacza, że element to Możemy dowolnie zakodować tę cechę na naszym kubicie lub na naszym Po raz kolejny, nie zawsze może istnieć pojedyncze mapowanie 1:1 z kolejności cech na kolejność kubitów, ponieważ różne mapy cech kodują różną liczbę cech na każdym kubicie. Ponownie ważne jest, abyśmy byli świadomi, gdzie kodowana jest każda cecha. Gdy podajemy listę parametrów do mapy cech , zakoduje ona cechę 0 z listy na najmniej znaczącym kubicie za pomocą parametryzowanej bramki, czyli na kubicie 0. Będziemy zatem stosować się do tej konwencji, wykonując to ręcznie. Zakodujemy na kubicie, a na kubicie.
Unitarny operator obwodu ZFM działa na stan początkowy w następujący sposób:
Wzór został przekształcony wokół iloczynu tensorowego, aby podkreślić operacje na każdym kubicie. Poniższy kod Qiskit używa bramek Hadamarda i bramek fazowych jawnie, aby pokazać strukturę ZFM:
qc0 = QuantumCircuit(1)
qc1 = QuantumCircuit(1)
qc0.h(0)
qc0.p(pi / 2, 0)
qc1.h(0)
qc1.p(pi / 3, 0)
# Combine circuits qc0 and qc1 into 1 circuit
qc = QuantumCircuit(2)
qc.compose(qc0, [0], inplace=True)
qc.compose(qc1, [1], inplace=True)
qc.draw("mpl", scale=1)

Teraz kodujemy ten sam wektor danych w obwodzie ZFM z trzema powtórzeniami, , używając klasy Qiskit z_feature_map, co razem daje nam kwantową mapę cech . Domyślnie w klasie z_feature_map parametry są mnożone przez 2 przed mapowaniem na bramkę fazową . Aby odtworzyć te same kodowania co powyżej, dzielimy przez 2.
from qiskit.circuit.library import z_feature_map
zfeature_map = z_feature_map(feature_dimension=2, reps=3)
zfeature_map = zfeature_map.assign_parameters([(1 / 2) * pi / 2, (1 / 2) * pi / 3])
zfeature_map.decompose().draw("mpl")

Wyraźnie widać, że jest to inne mapowanie niż to wykonane ręcznie powyżej, ale zwróć uwagę na spójność w kolejności parametrów: zostało ponownie zakodowane na kubicie.
Możesz używać ZFM za pośrednictwem klasy ZFM w Qiskit; możesz również użyć tej struktury jako inspiracji do skonstruowania własnego mapowania cech.
Mapa cech
Mapa cech (ZZFM) rozszerza ZFM poprzez włączenie dwukubitowych bramek splatających, konkretnie bramki obrotu , . Przypuszcza się, że ZZFM jest ogólnie kosztowna do obliczenia na komputerze klasycznym, w przeciwieństwie do ZFM.
realizuje interakcję i jest maksymalnie splatająca dla . można rozłożyć na serię bramek na dwóch kubitach, jak pokazano w poniższym kodzie Qiskit, używając bramki RZZ i metody klasy QuantumCircuit decompose. Kodujemy pojedynczą cechę wektora danych :
qc = QuantumCircuit(2)
qc.rzz(pi, 0, 1)
qc.draw("mpl", scale=1)

Jak to często bywa, widzimy to przedstawione jako pojedynczą jednostkę przypominającą bramkę, dopóki nie użyjemy .decompose(), aby zobaczyć wszystkie bramki składowe.
qc.decompose().draw("mpl", scale=1)

Dane są mapowane za pomocą obrotu fazowego na drugim kubicie. Bramka splata dwa kubity, na których działa, ze stopniem splątania określonym przez zakodowaną wartość cechy.
Pełny obwód ZZFM składa się z bramki Hadamard i bramki fazowej, jak w ZFM, a następnie splątania opisanego powyżej. Pojedyncze powtórzenie obwodu ZZFM to:
gdzie zawiera warstwę bramek ZZ o strukturze określonej przez schemat splątania. Kilka schematów splątania pokazano w blokach kodu poniżej. Struktura obejmuje również funkcję, która łączy cechy danych z kubitów będących splątane w następujący sposób. Powiedzmy, że bramka ma być zastosowana do kubitów i . W warstwie fazowej, te kubity mają bramki fazowe kodujące odpowiednio i . Argument bramki nie będzie po prostu jedną z tych cech lub drugą, ale funkcją często oznaczaną przez (nie mylić z kątem azymutalnym):
Zobaczymy to w kilku przykładach poniżej. Rozszerzenie na wiele powtórzeń jest takie samo jak w przypadku z_feature_map:
Ponieważ operatory stały się bardziej złożone, najpierw zakodujmy wektor danych za pomocą dwukubitowej ZZFM z jednym powtórzeniem, używając następującego kodu:
from qiskit.circuit.library import zz_feature_map
feature_dim = 2
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose(reps=1).draw("mpl", scale=1)

Domyślnie w Qiskit cechy są mapowane razem na za pomocą funkcji mapującej . Qiskit umożliwia użytkownikowi dostosowanie funkcji (lub , gdzie jest zbiorem par kubitów sprzężonych poprzez bramki ) jako krok wstępnego przetwarzania.
Przechodząc do czterowymiarowego wektora danych i mapując na czterokubitową ZZFM z jednym powtórzeniem, możemy zacząć widzieć mapowanie dla różnych par kubitów. Możemy również zobaczyć znaczenie "liniowego" splątania:
feature_dim = 4
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose().draw("mpl", scale=1)

W schemacie splątania liniowego pary kubitów o najbliższym sąsiedztwie (numerowane) w tym obwodzie są splątane. W Qiskit dostępne są inne wbudowane schematy splątania, w tym circular i full.
Mapa cech Pauli
Mapa cech Pauli (PFM) jest uogólnieniem ZFM i ZZFM do użycia dowolnych bramek Pauli. Mapa cech Pauli przyjmuje bardzo podobną formę do poprzednich dwóch map cech. Dla powtórzeń kodowania cech wektora
W przypadku PFM, jest uogólnione do unitarnego operatora ekspansji Pauli. Tutaj przedstawiamy bardziej uogólnioną formę dotychczas rozważanych map cech:
gdzie jest operatorem Pauli, . Tutaj jest zbiorem wszystkich łączności kubitów określonych przez mapę cech, w tym zbioru kubitów, na które działają bramki jednokubitowe. To znaczy, dla mapy cech, w której na kubit 0 działała bramka fazowa, a na kubity 2 i 3 działała bramka , zbiór zawierałby . przebiega przez wszystkie elementy tego zbioru. W poprzednich mapach cech funkcja była związana albo wyłącznie z bramkami jednokubitowymi, albo wyłącznie z bramkami dwukubitowymi. Tutaj definiujemy ją w sposób ogólny:
Dokumentację można znaleźć w dokumentacji klasy Qiskit Pauli feature map). W ZZFM operator jest ograniczony do .
Jednym ze sposobów zrozumienia powyższej operacji unitarnej jest analogia do propagatora w układzie fizycznym. Powyższa operacja unitarna jest unitarnym operatorem ewolucji, , dla Hamiltonianu , podobnego do modelu Isinga, gdzie parametr czasu jest zastępowany wartościami danych, aby sterować ewolucją. Rozwinięcie tego operatora unitarnego daje obwód PFM. Splątania łączące w można interpretować jako sprzężenia Isinga w sieci spinowej.
Rozważmy przykład operatorów Pauli i reprezentujących te oddziaływania typu Isinga. Qiskit udostępnia klasę pauli_feature_map do tworzenia PFM z wyborem jedno- i -kubitowych bramek, które w tym przykładzie zostaną przekazane jako ciągi Pauli ‘Y’ i ‘XX’. Zazwyczaj wynosi odpowiednio 1 lub 2 dla oddziaływań jedno- i dwukubitowych. Schemat splątania jest „liniowy”, co oznacza, że sprzężone są tylko najbliższe sąsiednie kubity w obwodzie kwantowym. Zauważ, że nie odpowiada to najbliższym sąsiednim kubitom na samym komputerze kwantowym, ponieważ ten obwód kwantowy jest warstwą abstrakcji.
from qiskit.circuit.library import pauli_feature_map
feature_dim = 3
pfmap = pauli_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1, paulis=["Y", "XX"]
)
pfmap.decompose().draw("mpl", scale=1.5)

Qiskit udostępnia parametr w mapach cech Pauliego, aby kontrolować skalowanie rotacji Pauliego.
Domyślna wartość to . Optymalizując jej wartość w przedziale, na przykład , można lepiej dopasować jądro kwantowe do danych.
Galeria map cech Pauliego
Tutaj wizualizujemy różne mapy cech Pauliego dla dwukubitowych obwodów, aby uzyskać lepszy obraz zakresu możliwości.
from qiskit.visualization import circuit_drawer
import matplotlib.pyplot as plt
feature_dim = 2
fig, axs = plt.subplots(9, 2)
i_plot = 0
for paulis in [
["I"],
["X"],
["Y"],
["Z"],
["XX"],
["XY"],
["XZ"],
["YY"],
["YZ"],
["ZZ"],
["X", "ZZ"],
["Y", "ZZ"],
["Z", "ZZ"],
["X", "YZ"],
["Y", "YZ"],
["Z", "YZ"],
["YY", "ZZ"],
["XY", "ZZ"],
]:
pfmap = pauli_feature_map(feature_dimension=feature_dim, paulis=paulis, reps=1)
circuit_drawer(
pfmap.decompose(),
output="mpl",
style={"backgroundcolor": "#EEEEEE"},
ax=axs[int((i_plot - i_plot % 2) / 2), i_plot % 2],
)
axs[int((i_plot - i_plot % 2) / 2), i_plot % 2].title.set_text(paulis)
i_plot += 1
fig.set_figheight(16)
fig.set_figwidth(16)
Powyższe można oczywiście rozszerzyć o inne permutacje i powtórzenia macierzy Pauliego. Zachęcamy uczących się do eksperymentowania z tymi opcjami.
Przegląd wbudowanych map cech
Poznałeś kilka schematów kodowania danych w obwodzie kwantowym:
- Kodowanie bazowe
- Kodowanie amplitudowe
- Kodowanie kątowe
- Kodowanie fazowe
- Kodowanie gęste
Zobaczyłeś, jak konstruować własne mapy cech przy użyciu tych schematów kodowania, oraz cztery wbudowane mapy cech, które wykorzystują kodowanie kątowe i fazowe:
- Efficient SU2
- Z feature map
- ZZ feature map
- Pauli feature map
Te wbudowane mapy cech różniły się od siebie na kilka sposobów:
- Głębokość dla danej liczby zakodowanych cech
- Liczba kubitów wymagana dla danej liczby cech
- Stopień splątania (oczywiście związany z pozostałymi różnicami)
Poniższy kod stosuje te cztery wbudowane mapy cech do kodowania zestawu cech i wykreśla dwukubitową głębokość powstałego obwodu. Ponieważ współczynniki błędów dwukubitowych są znacznie wyższe niż współczynniki błędów bramek jednokubitowych, można by rozsądnie być najbardziej zainteresowanym głębokością bramek dwukubitowych. W poniższym kodzie uzyskujemy liczbę wszystkich bramek w obwodzie, najpierw dekomponując obwód, a następnie używając count_ops(), jak pokazano poniżej. Tutaj dwukubitowe bramki, którymi jesteśmy zainteresowani, to bramki 'cx':
# Initializing parameters and empty lists for depths
x = [0.1, 0.2]
n_data = []
zz2gates = []
su22gates = []
z2gates = []
p2gates = []
# Generating feature maps
for n in range(3, 10):
x.append(n / 10)
zzcircuit = zz_feature_map(n, reps=1, insert_barriers=True)
zcircuit = z_feature_map(n, reps=1, insert_barriers=True)
su2circuit = efficient_su2(n, reps=1, insert_barriers=True)
pcircuit = pauli_feature_map(n, reps=1, paulis=["XX"], insert_barriers=True)
# Getting the cx depths
zzcx = zzcircuit.decompose().count_ops().get("cx")
zcx = zcircuit.decompose().count_ops().get("cx")
su2cx = su2circuit.decompose().count_ops().get("cx")
pcx = pcircuit.decompose().count_ops().get("cx")
# Appending the cx gate counts to the lists. We shift the zz and Pauli data points,
# because they overlap.
n_data.append(n)
zz2gates.append(zzcx - 0.5)
z2gates.append(0)
su22gates.append(su2cx)
p2gates.append(pcx + 0.5)
# Plot the output
plt.plot(n_data, p2gates, "bo")
plt.plot(n_data, zz2gates, "ro")
plt.plot(n_data, su22gates, "yo")
plt.plot(n_data, z2gates, "go")
plt.ylabel("CX Gates")
plt.xlabel("Data elements")
plt.legend(["Pauli", "ZZ", "SU2", "Z"])
# plt.suptitle('zz_feature_map(n)')
plt.show()
Ogólnie mapy cech Pauli i ZZ będą skutkować większą głębokością obwodu i większą liczbą bramek dwukubitowych niż mapy cech efficient_su2 i Z.
Ponieważ mapy cech wbudowane w Qiskit mają szerokie zastosowanie, często nie będziemy musieli projektować własnych, zwłaszcza na etapie nauki. Jednak eksperci w dziedzinie kwantowego uczenia maszynowego prawdopodobnie wrócą do tematu projektowania własnych odwzorowań cech, gdy zmierzą się z dwoma skomplikowanymi wyzwaniami:
-
Nowoczesny sprzęt: obecność szumu i duży narzut kodu korekcji błędów oznacza, że dzisiejsze zastosowania będą musiały uwzględniać takie rzeczy jak wydajność sprzętowa i minimalizacja głębokości bramek dwukubitowych.
-
Odwzorowania pasujące do danego problemu: czym innym jest stwierdzenie, że na przykład
zz_feature_mapjest trudna do klasycznej symulacji i przez to interesująca. Czym innym jest to, żezz_feature_mapjest idealnie dopasowana do Twojego zadania uczenia maszynowego lub zestawu danych. Wydajność różnych sparametryzowanych obwodów kwantowych na różnych typach danych jest aktywnym obszarem badań.
Kończymy notatką o wydajności sprzętowej.
Odwzorowanie cech efektywne sprzętowo
Sprzętowo wydajne odwzorowanie cech to takie, które uwzględnia ograniczenia rzeczywistych komputerów kwantowych, w celu redukcji szumu i błędów w obliczeniach. Przy uruchamianiu obwodów kwantowych na komputerach kwantowych bliskiej przyszłości istnieje wiele strategii łagodzenia szumu nieodłącznie związanego ze sprzętem. Jedną z głównych strategii dla wydajności sprzętowej jest minimalizacja głębokości obwodu kwantowego, tak aby szum i dekoherencja miały mniej czasu na zakłócenie obliczeń. Głębokość obwodu kwantowego to liczba kroków bramek wyrównanych w czasie wymaganych do ukończenia całego obliczenia (po optymalizacji obwodu)[5]. Przypomnij sobie, że głębokość abstrakcyjnego, logicznego obwodu może być znacznie niższa niż głębokość po transpilacji obwodu dla rzeczywistego komputera kwantowego.
Transpilacja to proces przekształcania obwodu kwantowego z wysokopoziomowej abstrakcji do postaci gotowej do uruchomienia na rzeczywistym komputerze kwantowym, z uwzględnieniem ograniczeń sprzętu. Komputer kwantowy ma natywny zestaw bramek jedno- i dwukubitowych. Oznacza to, że wszystkie bramki w kodzie Qiskit muszą zostać przetranspilowane do zestawu natywnych bramek sprzętowych. Na przykład w ibm_torino, QPU wyposażonym w procesor Heron r1 i ukończonym w 2023 roku, natywne lub bazowe bramki to {CZ, ID, RZ, SX, X}. Są to dwukubitowa bramka sterowana-Z oraz bramki jednokubitowe zwane odpowiednio identycznością, rotacją , pierwiastkiem kwadratowym z NOT i NOT, tworząc zestaw uniwersalny. Podczas implementacji bramek wielokubitowych jako równoważnego podobwodu wymagane są fizyczne dwukubitowe bramki , wraz z innymi jednokubitowymi bramkami dostępnymi w sprzęcie. Dodatkowo, aby wykonać bramkę dwukubitową na parze kubitów, które nie są fizycznie sprzężone, dodawane są bramki SWAP w celu przenoszenia stanów kubitów między kubitami, aby umożliwić sprzężenie, co prowadzi do nieuniknionego wydłużenia obwodu. Używając argumentu optimization, który można ustawić od 0 do najwyższego poziomu 3. Dla większej kontroli i możliwości dostosowania, potokiem transpilera można zarządzać za pomocą Qiskit Pass Manager. Więcej informacji o transpilacji znajdziesz w dokumentacji transpilera Qiskit.
W pracy Havlicek i in. 2019 [2] jednym ze sposobów, w jaki autorzy osiągają wydajność sprzętową, jest użycie mapy cech , ponieważ jest to rozwinięcie drugiego rzędu (patrz sekcja „ feature map” powyżej). Rozwinięcie -tego rzędu ma -kubitowe bramki. Komputery kwantowe IBM® nie mają natywnych -kubitowych bramek, gdzie , więc ich implementacja wymagałaby dekompozycji na dwukubitowe bramki CNOT dostępne w sprzęcie. Drugim sposobem, w jaki autorzy minimalizują głębokość, jest wybór topologii sprzężenia , która odwzorowuje się bezpośrednio na sprzężenia architektury. Kolejną optymalizacją, którą podejmują, jest wybranie wydajniejszego, odpowiednio połączonego podobwodu sprzętowego. Dodatkowe rzeczy, które należy wziąć pod uwagę, to minimalizacja liczby powtórzeń mapy cech i wybór dostosowanego niskogłębokościowego lub „liniowego” schematu splątania zamiast „pełnego” schematu, który splątuje wszystkie kubity.

Powyższa grafika pokazuje sieć węzłów i krawędzi, które reprezentują odpowiednio fizyczne kubity i sprzężenia sprzętowe. Mapa sprzężeń i wydajność ibm_torino pokazana jest ze wszystkimi możliwymi dwukubitowymi bramkami sprzężenia CZ. Kubity są oznaczone kolorami w skali opartej na czasie relaksacji T1 w mikrosekundach (μs), gdzie dłuższe czasy T1 są lepsze i mają jaśniejszy odcień. Krawędzie sprzężeń są oznaczone kolorami według błędu CZ, gdzie ciemniejsze odcienie są lepsze. Informacje o specyfikacji sprzętu są dostępne w schemacie konfiguracji backendu sprzętowego IBMQBackend.configuration().
Bibliografia
- Maria Schuld i Francesco Petruccione, Supervised Learning with Quantum Computers, Springer 2018, doi:10.1007/978-3-319-96424-9.
- Vojtech Havlicek i in., „Supervised Learning with Quantum Enhanced Feature Spaces.” Nature, vol. 567 (2019): 209–212. https://arxiv.org/abs/1804.11326.
- Ryan LaRose i Brian Coyle, "Robust data encodings for quantum classifiers", Physical Review A 102, 032420 (2020), doi:10.1103/PhysRevA.102.032420, arXiv:2003.01695.
- Lou Grover i Terry Rudolph. „Creating Superpositions That Correspond to Efficiently Integrable Probability Distributions.” arXiv:quant-ph/0208112, 15 sierpnia 2002, https://arxiv.org/abs/quant-ph/0208112.
- Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, José I. Latorre, "Data re-uploading for a universal quantum classifier", Quantum 4, 226 (2020), ArXiv.org/abs/1907.02085.
- Maria Schuld, Ryan Sweke, Johannes Jakob Meyer, "The effect of data encoding on the expressive power of variational quantum machine learning models", Phys. Rev. A 103, 032430 (2021), arxiv.org/abs/2008.08605
import qiskit
qiskit.version.get_version_info()